Database (esempi)
 |
DBRDatabase of Rhythms
Samples Menus: |
The Corpus of Latin rhythms. An open digital edition of music and texts
The Corpus of Latin Rhythms 4th-9th Century is the corpus of the first Latin poems in stressed non quantitative versification, a collection of texts whose forms and varieties cannot otherwise be consulted in their entirety. In fact, as is well known, less than a third of the texts have been published in a discontinuous manner in the six volumes of the Poetae Latini aevi Carolini of the Monumenta Germaniae Historica by Dümmler, Traube, Strecker and Fickermann (1881-1953). But the greater part, which the Monumenta had excluded from their editorial project, were only published in the Analecta Hymnica on the basis of philological criteria which are no longer accepted, or in manuscript Catalogues, in magazines, in single author editions, whilst other texts are still unpublished. In addition to the texts already published in the Monumenta Germaniae Historica, many manuscripts unknown to the previous editors have been made available during the last ten years and in some cases these texts significantly modify the tradition's attitude. So the thought of collecting an entire Corpus of early Medieval rhythmic tests arises, one which would allow the complete documentation of the rhythmic phenomenon through the centuries since its formation, and would consequently permit the collection of homogenous data. Above and beyond the editing, the scientific objective is the study of the origin of this versification and the utilisation of rhythms as documentary evidence of the transition from Latin to early Romance.
From 1998 to 2000 the research group composed of various European universities met at three annual conventions: in Arezzo (Italy), in Ravello (Italy) and in Munich (Germany) and set in place the basis of the first collected edition. The census-taking phase for the texts and manuscripts initiated by Konrad Vollmann and Alessandra Terracina gathered a list of over 700 texts handed down from over 1500 manuscripts which do not belong to a single tradition and even less so to a single recensio. The initial explorative transcriptions were carried out with great generosity by Konrad Vollmann, Pascale Bourgain, Peter Stotz, Carlos Pérez González, Edoardo D'Angelo, Paolo Zanna, Corinna Bottiglieri, and the Paleography group in Arezzo[1]. Whilst there was a significant increase of texts and testimonial manuscripts compared to the number expected, there would be difficulty with the rhythms when recourse was made to the traditional so-called lachmanian editorial model. The objective of this model is the reconstruction of a single archetypal text, if not the actual original text, on the basis of the existing attestations. As is also the case with other medieval text typologies, it is well known that the application of this model in most cases does not suite Medieval Latin poetry. Furthermore, just as for texts, the model of philological fidelity to history is no longer considered to be suitable for architectural structures or for the restoration of frescoes either.
As is well known, a philological tendency has recently developed which utilises an individual document, or better, utilises the version of the text handed down from every individual manuscript (the scribal version, which corresponds to Segre's diasistema) with their individual histories, environmental settings, their patron, and their intentions and purposes. This approach of "new philology" has been defined in an implicit contrast with an old and sometimes merely arbitrarily reconstructive philology.
All of which naturally leads to a discussion of method. However, this cannot take place within this sitting. Nevertheless, that the tendency to respect the textual form effectively attested to by tradition as far as possible must be verified independently of the definitions, if not rejecting then limiting amendments to a minimum, thereby devaluing reconstruction's usefulness and scientific reliability when based on incompatible editing. As has been stated recently, "all things considered, the critical text has a relative value, in as much as it is sooner or later destined to be superseded; the testimonies preserve an absolute value: once recorded they can serve for every succeeding edition"[2]. Given the richness of traditional manuscripts of Medieval Latin work, the imposition of these criteria requires the adoption of objectives for the material's representation which would be impossible to achieve using printing technology, but which are possible to confront with computing Technology. This opens the way to philological methodologies which bring philology closer to paleography and to archives studies where the value is in the document, perhaps thereby distancing it from literary criticism in which the value is in the author's product. However, a consciousness that this is not possible for the early Medieval period has developed.
This requirement for historical fidelity is all the more sensitive and justified in a tradition such as this of poetry frequently associated with musical notation, which very often varies from manuscript to manuscript and cannot always be brought back to a communal melodic schema. In this way, in an edition of this poetry, the Corpus sets out the first experience of interdisciplinary philology which is both textual and musical. The interest in the musical edition of the text's historical forms (edited by Sam Barrett through work lasting many years), has also brought about the inclusion of the transcriptions of the melody on staff as interpreted in the past by scholars such as Coussemaker, Sesini, Vecchi etc. Giacomo Baroffio and his choir have recorded the vocal execution of these transcriptions. The edition therefore presents the texts in six different forms:
| - manuscript reproduction, - diplomatic transcription of the verbal text, - diplomatic musical transcription of the neumas - alfanumeric musical transcription of the notation - "historical" transcription on staff of the medieval melody - vocal execution of the "historical" transcription. |
According to Domenico De Robertis, who in Florence has just published a monumental critical edition of Dante's Rhyme, the ideal critical edition is that which "offers the necessary and sufficient material for another critical edition of the same work to be carried out according to different criteria"[3]. Following this line of argument the Corpus proposes a type of "open" edition offering a critical collection of material capable of being re-used in different scientific projects. In fact, the Corpus includes all the textual versions as autonomous entities, furnishing a reproduction of the relative sources, and associating it with the manuscript's musical version and sung execution of the relative historical transcriptions. The only way currently known to achieve such a compendium of textual forms in different languages is through Computing Technology. Therefore, a database of the rhythms has been produced, named by the acronym DBR, in which all the text's versions can be consulted - whether verbal or musical - enabling their comparison with the original manuscript document. A model has therefore been constructed in which beside the reconstruction by the editor, which usually is called an "edition" , the text is readable in the real attested versions on manuscript documents in their autonomous entirety, and so not in the historically abnormal form of variations of a hypothetical original. This process, without giving up the perception of the entire tradition, overcome the distinction between a Text reconstructed by the editor and the many transmitted texs, usually shattered, misrepresented and left unrecognizable in the apparatus of the variants.
The programming of specific software has allowed complete cataloguing of the texts on the basis of their metrical and linguistical characteristics in addition to their musical and philological aspects. This allows the metrical and the linguistic or historical data to be cross-referenced in the consultation. This allows researchers to select, for example, the VII century Burgundy texts in rhythmical septenaries, or the e/i exchanges in the IXth century texts, or the musical typologies associated with a certain metrical schema, or the association between a particular lay-out and a certain type of text.
The project's completion has required the elaboration of transcription norms for both the text and the music which are adaptable for the computer, and has given boost to the research for new systems of linguistic and metrical description. To achieve this end, , firstly, interrogative grids have been placed in the DBR, under the guidance of Peter Stotz, grids which are based on the linguistic standards of classical Latin; secondly, there are experimental grids proposed by Michel Banniard (see above); thirdly, cataloguing of the versification according to Norberg's criteria has been included; and lastly, experiments in new classification proposed by Edoardo D'Angelo too.
The edition's first CD-ROM, which concerns only the musical rhythms transmitted in non-liturgical manuscripts, is in the final stages of completion on the IT platform now about to be explained, and which should be completed by next year. Future issues will firstly concern calendar rhythms, of which a great many musical versions have been found, then the rhythmic hymns, therefore the epigraphic rhythms and so on. This first volume included well-known texts such as the Planctus for Charlemagne's death, that for the Duke Henry of Friuli, and of Abbot Ugo, the planctus for the Battle of Fontenoy, as well as moral texts, biblical texts, and poetical songs by Paolinus of Aquileia and by Gottschalk of Orbais. In general, the examples are amongst the most important and most beautiful of early Medieval rhythmic literature. The aim of this edition is to contribute to the recovery and sampling of their original character of musical lyric, and to study the production of this musical poetry in a context not liturgical, even if certainly spiritual and ritual, presenting also the edition of the most ancient medieval text set to music.
Various humanistic disciplines are touched upon by the scientific questions raised by the elaboration of the software. The application of the semi-diplomatic method is a problem in itself, even if only for the energy and resources required, in the case of ramified traditions lacking true distinct versions. More specifically, the linguistic cataloguing, which must of necessity be applied to individual transcriptions, involves a degree of arbitrariness in defining the observed phenomena. Furthermore, this kind of arbitrary decisions extends still further to the choice of whether or not to record a specific phenomenon as distinct. For example, it is often difficult to establish if amico suscipit can be recorded as fading of final -m or as ablative pro accusative. For this reason the classification has remained relatively wide, thereby leaving the user a greater margin of interpretation. Problems of statistical standardisation of research results arose during the same process of cataloguing. When a linguistic phenomenon is present in 5 out of the 7 transcriptions of a text, but another linguistic phenomenon only goes back to an attested text in an individual manuscript, it must be remembered that the 5:2 recurrence does not reflect the real distribution of the phenomena.
In an analogous manner should be evaluated the initial results of the "Romance" linguistic and socio-linguistic cataloguing. Whilst the A solis ortu rhythm is marked, for example, by a degree 1,09 of Subject/Verb separation, a degree 0, 28 of Noun/Adjective/Participle separation, and an absolute frequency 12/24 (0, 5) of prepositional locution, Paulinus of Aquileia's planctus Mecum Timavi produces a degree of Noun/Verb separation of 3, 32, N/A/P 0, 52, which is a 27/35 (0, 306) prepositional locution frequency. This demonstrates that a learned author such as Paulinus of Aquileia kept to, in this rhythm, a more classical syntactic word arrangement and more archaic use of prepositions compared to the Planctus Karoli's anonymous writer, or that the latter adopted a more popular linguistic register.
Still on the linguistic features, the analysis of a text through generic research engines or analytical linguistic software such as TUSTEP or TACT is inapplicable if, instead of the base-version ("edition"), the analysis is attempted on the individual diplomatic transcriptions with all their apparatus of conventional signs and their incongruous breaking of lines and words. In this case too, planning the use of different instruments for the differents research fields is necessary. A linguistic research engine is necessary in order to find the forms in individual transcribed versions; and in base-versions more refined software is required for the study of associations between terms, lexical recurrences, and simile.
In the production of the apparatus of loci paralleli, the source registration scheme in the database edition does not represent significant progress when compared to the traditional editions, although it will be possible to research a certain text or a specific author by name in the digital edition within the apparatus of all texts or groups of texts. For this specific aim, it would have been interesting to experiment with, for example, the hypertext edition that would have opened the texts in which an individual word appears with a simple click of the mouse, thereby creating an immediately visible network of connections. However, this operation is not possible in a database which is not provided with a connection to a word-processing program such as "Word for Windows", whose purchase cannot be imposed to the users. In order to obtain the major benefits of a comprehensive edition, a secondary advantage in text observation has therefore had to be sacrificed.
THE DBR
The DBR (Rhythms Database) is a piece of software initiated in 1999 by Giacomo Desideri and his GDC (alpha version), and brought to fruition (Beta version) by Marco Meucci at MARTEK in 2002 according to a project of mine. His aim is to hold and order the data and the materials of the IV-IX century Corpus of Latin Rhythms, providing the platform essential to the development of the CD-R, which is the first critical edition on digital supporto of a Medieval Latin corpus. The final product will have a notably different interface to the highly articulated one presented here, and will also make possible access to data via multilingual Menus.
The present program's structure is one of a chain of visualisable database tables in a grid of over 150 fields and underfields of observation, in a series of screens which correspond to the edition's scientific setting up. Between them the tables connect the metrical, linguistic, philological and musicological data, the visual files containing the images of the manuscript, and the musical transcriptions (through the XnView program which allows all existing formats to be read), as well as the audio files (in Wave format) containing the vocal execution of the melodies. The program is supported on the platforms of Windows XP Professional, Windows Millenium Edition or Windows 2000. All the tables and data will have to be cross-referenced so that it will be possible to consult them through the Search menus.
In the general display the text is classified according to the usual data: author, date, place of origin, ICL number, manuscript number, manuscript number not used in previous editions, and editing number.
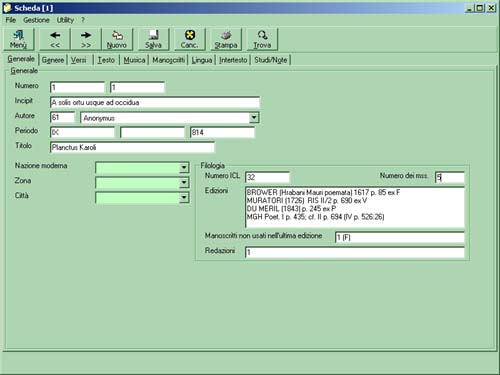
The General Menu contains the relevant data for the text's literary genre as well as the text's theme.
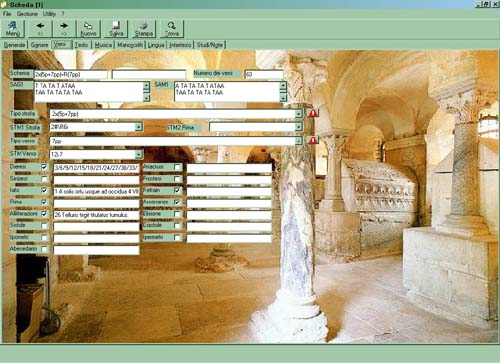
The Versification Menu displays the rhythmic-metrical data according to differentiated analysis grids. Firstly, the verse scheme and strophe scheme are analysed according to Norberg's criteria. Then they are analysed according to the new criteria elaborated by Edoardo D'Angelo and illustrated in the contribution published in this volume. In addition, this menu records the absence or presence of hiatus, elision, apheresis, syneresis, rhyme, alliteration, hypermetrical or hypometrical lines, etc. A further benefit of this menu is analysis of the text according to the sequence of grammatical accents (SAG). That is to say, the series of atonics and tonics based on the prosaic prosody compared with the sequence of metrical accents (SAM), which are the tonic-atonic successions according to those expected from the rhythmic verse schema used in the text. The objective of this double indexing is to allow the analysis and comparison of the "rhythmic" prosody and the linguistic prosody, about which there is much discussion[4].
The Text Menu is the heart of the program and therefore of the edition, and is based more upon the individual manuscript versions than upon the "philological" (i.e. theoretical) reconstruction of an archetype.The opening of this menu shows the list of manuscripts containing the text in question.
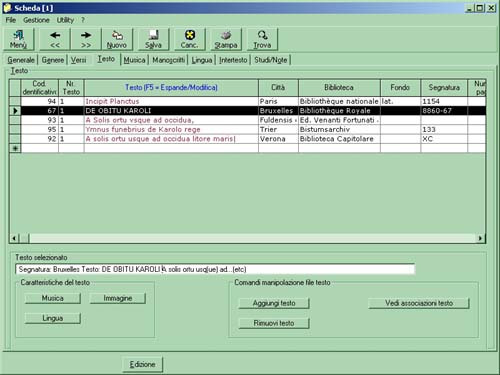
Highlighting the individual manuscript automatically selects the text version and the music associated with that version. Through this it is possible to activate the relevant image and the text transcription, which has been carried out according to specific norms, and this can be checked comparing it with the manuscript's image upon which it has been executed. Two submenus can be brought down and can be activated from the position of a manuscript witness. These are Language and Music. By selecting the Language option a new dialogue box appears which presents the linguistic characteristics of this version of the text, subdivided into areas of interrogation.
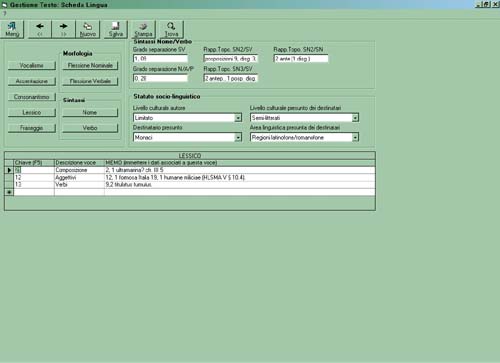
These areas of interrogation are: comparison with the "classical" grammar through the usual divisions Phonetics (consonantal and vocalism) - Accentuation - Morphology - Syntax - Lexicon and Phraseology. Each of these has its own subdivisions as applied using Peter Stolz's manual of medieval Latin language, but also new fields of observation such as those suggested by Michel Banniard, namely Absolute nominal locution frequency and Relative nominal locution frequency and Relative nominal locution frequency, or Idiomatic locution in long segments and Idiomatic locution in short segments. An experimental grid has been provided in order to interrogate the noun/verb syntactical relationships, with observations on the reciprocal positions between subject and verb and between noun and preposition being provided. Furthermore, the sociological statute on authorship and addressee as presupposed from the text's linguistic level can be interrogated: data which should help statistical elaboration on the proximity to the spoken Latin or the early "Romance" language as used in these poems, and on the social strata of origin and fruition.
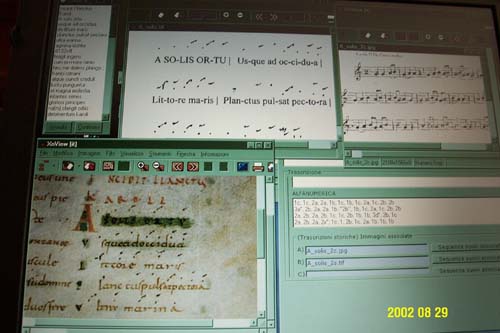
Through the menu's Music option a new dialog box appears on the screen that presents all the included information about the music accompanying the specific version of the text under examination. The manuscript's image appears along with the neums, the traditional musical transcription, and the alphanumeric transcription according to Sam Barrett's system. This system converts the notes and other characteristics that the musical signs communicate into numbers and letters thereby making these readable by the computer and so queries can be be run on them. Furthermore, there is essential data on the features of notation and its dating, and a synthetic analysis of the melody's relationship with the text, along with comparison (concordance) with the transcriptions of other melodies referring to the same text. Reproduction of the historical transcription on staff produced by eighteenth and twentieth century musicologists is also available, and these are connected by a simple mouse click on the appropriate button to one or more recordings by Giacomo Baroffio of the vocal execution of these historical transcriptions.
Therefore six different forms of the selected text can be consulted by viewing one single screen: the reproduction of the manuscript, its text transcription, the transcription of the neuma, the alphamuneric transcription, the musical transcription on staff, and the latter's vocal execution.
The Paleographic Menus are accessed from the Text Menu by using the line relating to every manuscript. The Paleographic Menus have information on shelf-mark, dating, origin, format, support, code use characteristics, and more specifically on lay-out, graphics, and further reproduction of the page containing the "rhythms" in question, as well as the names of the scholars responsible for the collation.
An Edition button brings a legible philological reconstruction up on the screen, if the attested versions allow to make it without loosing linguistic or metrical data. Otherwise the transcription chosen by the editor as "base-text" appears, if there are more versions of the text which can not traced back to a common original without loss of information.
Further menus concern the Intertext, with tripartition of the cited texts into sources, comparisons and Fortleben: reuses, quotations or rewritings. There is also a Studies and Notes menu (Bibliography and comments by the editors).
The manuscript's data can be accessed directly from the external menu by selecting the Manuscript button. A Search can be initiated by using the same Menu, allowing a data search on any element in the entire DBR cataloguing/indexing. For example, a search can be made for the ninth century texts which contain "hiatus" and are of Burgundian origin, or where and how many times a certain melodic sequence occurs and which associated metrical structure is preferred, or which themes most often occur in association with them. The search is activated by selecting the three elements of data-hiatus-location: after a few seconds the resulting list of matching texts appears on the screen.
This structure, planned for the data's introduction, has to be simplified for the final CD- There will be a new interface with instructions and menus in various languages, reflecting the philological approach of the Corpus, which aims at recovering the plurality of the text forms and their linguistic forms, their musical dimension, so nearing the original orality and original qualities of the performance: features that a printed edition is not capable of restoring. Therefore, the utilisation of multimedia support in order to apply a philological approach intends to adhere more closely to the historical reality and to the hypotetical fruition context and to experiment techniques of interdisciplinary analysis, the results of which will be able to furnish scholars with important contributions.
|
Data of the first CD-ROM: 28 texts in 145 versions of attested manuscripts |
[1 ]For the history of the project see F. Stella, Introduzione a Poetry of the early medieval Europe, 2002, pp. ix-xii, and K. Vollmann, ibid., pp. xiii-xviii; for the scientific outlines of the digital edition according to the "new philology" Id., Problemi ecdotici dei ritmi.
[2] M. Dorigatti, Concordanze, rimario e testo critico: il caso del Boiardo, in: "Studi e problemi di critica testuale", XL (I semestre 1990), pp. 51-67, here pp. 58-59.
[3] Cit. in Mordenti 67, senza indicazione bibliografica.
[4] See P. Klopsch, Der Übergang von quantitierenden zu akzentuierenden lateinischen Dichtung, in Metrik und Medienwechsel-Metrics und Media, ed. by Hildegard Tristram, Tübingen 1991.
REFERENCES
L. Perilli, Filologia Computazionale, Roma 1997
Patrick Sahle, Digitale Edition (Historischer Quellen) - einige Thesen (1997)
www.uni-koeln.de/~ahz26/dateien/thesen.htm
L. Leonardi (ed.) Testi, manoscritti, ipertesti. Compatibilità informatica e letteratura medievale. Atti del convegno internazionale Firenze, Certosa del Galluzzo, 31 maggio- 1 giugno 1996, Firenze, SISMEL 1998
M. Ansani, Diplomatica (e diplomatisti) nell'arena digitale, in "Scrineum" 1 (1999), 1-11. http://scrineum.unipv.it/biblioteca/ansani.htm
F. Stella, Problemi ecdotici dei ritmi, o filologia di testi irregolari: le risorse dell'edizione in forma di data-base, in Poesia dell'alto medioevo europeo: manoscritti, lingua e musica dei ritmi latini. Acts of the Euroconference for the Corpus of Latin rhythms (IV-IX century), Arezzo 6-7 November and Ravello, 9-12 September 1999, pp. 241-256
E. D'Angelo-F. Stella (eds.), Poetry of early medieval Europe: manuscripts, language and music of the rhythmical Latin texts. III Euroconference for the digital edition of the Corpus rhythmorum, München 4-6 November 2000, Firenze, SISMEL, 2003 (forthcoming).
K. Uhde, Documenti in Internet - Forme di presentazione nuove d'antichi documenti d'archivio, in "Scrineum" 2 (2000) http://scrineum.unipv.it/biblioteca/kuhde.htm
Andrea Zorzi, Documenti, archivi digitali, metafonti, in http://www.storia.unifi.it/_PIM/AIM/metafonti.htm
e-philology. Introduzione, by G.P. Maggioni, in http://www.e-philology.net
Raul Mordenti, Informatica umanistica, Roma 2002, with updated bibliography.
Giovanna Alvoni, Scienze dell'antichità per via informatica, Bologna 2002 (Italian edition of Altertumswissenschaften digital, Hildesheim 2001).
I am grateful to Clive Prestt for his help in the English translation from Italian.

